

Clubhouse is probably our best hope for training an AI to communicate like a human
Clubhouse is probably our best hope for training an AI to communicate like a human

In this post, I cover some of the high-level challenges associated with doing true natural language processing — not just written language, but spoken language as humans have used it for millennia. Training machines not just to write like humans, but to speak like them, is partly a data availability problem. But luckily there’s a source of such conversational speech data now available to us: the drop-in audio app Clubhouse.
Summary:
Natural human language is continuous, while modern textual representations of language are discrete.
This distinction between discrete and continuous matters for how we build and train AI.
Writing can be thought of as a form of quantization of language, where critical information is lost. Reading can be thought of as the kind of upsampling that some newer ML models are doing.
Spoken communication skips this downsampling/upsampling process, and retains far more context. It’s therefore desirable in both translation and language generation contexts.
Training data consisting of digitized human conversation is hard to come by in privacy-constrained nations.
Clubhouse would be a great source of such training data.
The majority of humanity’s present AI efforts are a bit like the drunk who looks for his keys under the light post because that’s where the light is. We tend to work on problems for which we can easily get vast quantities of training data — this is especially true in the realm of natural language processing (NLP), where our NLP systems are trained on the hundreds of terabytes of textual data drawn from the open web.
But these textual representations of language have an important difference from spoken (or signed) languages: text is discrete, whereas speech is continuous.
So what we call “natural language processing” is actually misnamed. It’s better termed “Written Language Processing,” because the natural language that humans use with one another is vocal and aural — or, in the case of some languages, visual.
To really do “natural” language processing, so that we can speak to an AI and it speaks back with an appropriately inflected, natural-sounding response, we’ll need to train our models on human conversation — millions of hours of human conversation. We’ll need at minimum a volume of speech that contains a number of words on the order of the ~200TB of text in the common crawl dataset.
That’s a tall order, and right now there’s only one place (in the West) I can think of where there are millions of hours a day of conversation that meets the following criteria:
Digital audio format
No expectation of privacy on the part of the users — they’re dialoguing in public, for public consumption
Mostly consists of actual back-and-forth exchanges (this rules out YouTube, or even podcasts)
That place is Clubhouse, and while the dialogues happening on that app aren’t completely natural and informal — there’s a performative aspect to most of it — it’s closer to a giant digital trove of humans talking to each other than anything else that exists in English.
China, of course, can just suck up all the audio it wants from its citizens’ private conversations, so it doesn’t have data collection as a barrier to this particular innovation. But outside China, Clubhouse is the only game in town.
Why “discrete vs continuous” matters for NLP
You may think I’m nitpicking with this business about text vs. speech, but I hope to convince you that I’m doing anything but. This is a distinction so deep it almost qualifies as fundamental.
Take a look at this diagram from a recent paper by the Facebook AI team, Self-supervised learning: The dark matter of intelligence.
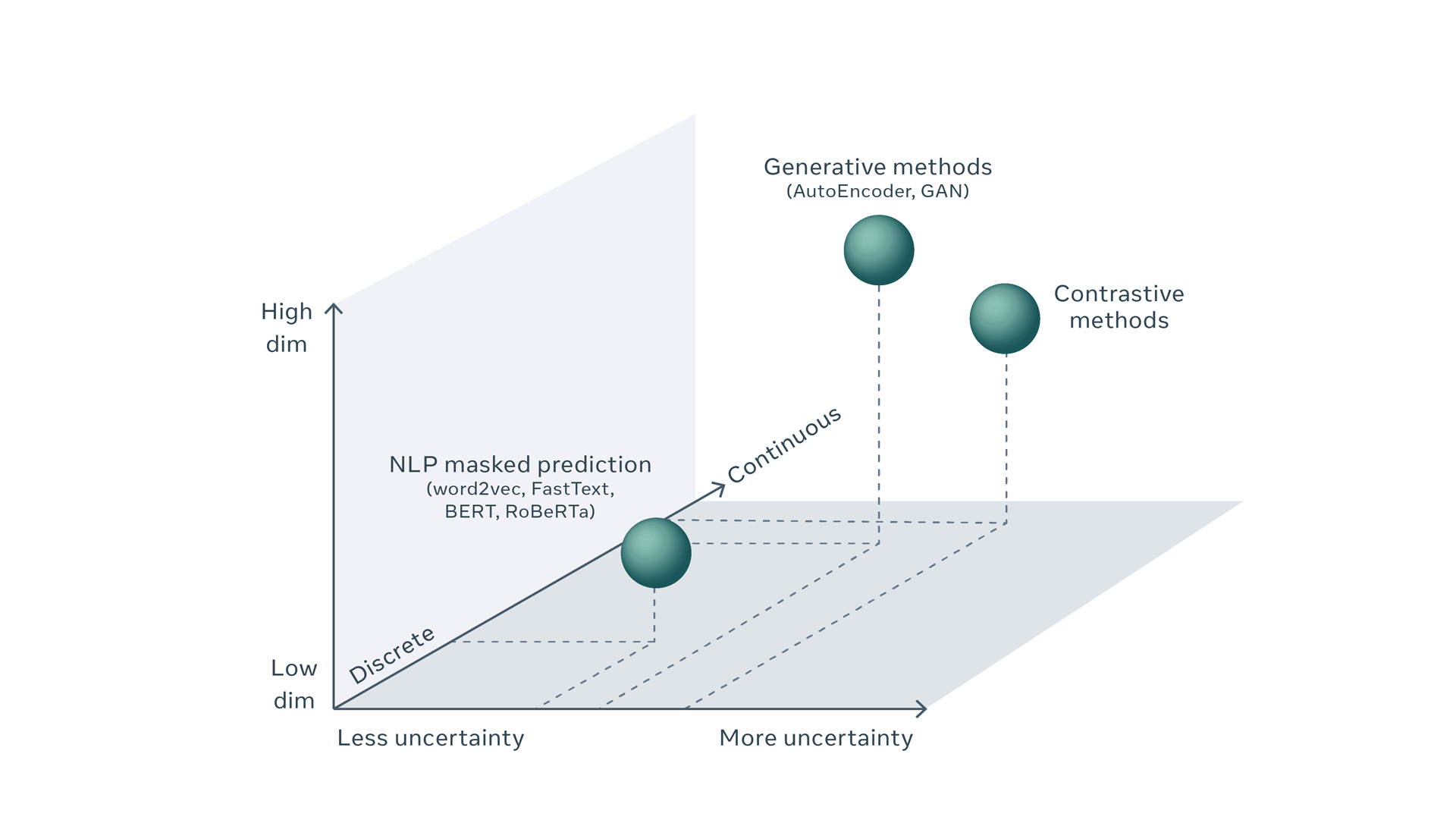
Don’t worry if this diagram doesn’t make much sense to you — it’s a pretty bad diagram. What mainly interests me in it are the three axes:
Dimensionality: The number of categories the model is trying to reason about and apply to an input signal, in order to either classify (e.g., is this a picture of a stop sign?) or to figure out the next token in a sequence (e.g., what sentence should I spit out in response to what the user just typed in?)
Uncertainty: This axis won’t concern us directly in this post, but it’s basically about the level of confidence the model can have in figuring out which categories might best fit this input.
Discrete <=> continuous: This is easiest to explain with an example. Text is discrete, in that the boundaries between words on a page or screen are clear; so textual input comes in the form of tokens the model can analyze, categorize, and otherwise reason about. Audio, in contrast, is composed of continuous sound waves; before we can analyze audio, we have to chop it up into discrete words and phrases.
Models that deal with written language operate more towards the origin on the above graph — discrete, lower-dimensional, with moderate to lower levels of uncertainty. These aspects make them much more tractable to our current ML systems than continuous problems, both in terms of the amount of hardware we can throw at them and the algorithms available to us. (For a whole ton of reasons that paper gets into, continuous is a lot harder than discrete.)
But the real world is not composed of written language or anything close to it. Actual reality — at least in the size regime that matters to everyone who isn’t doing quantum physics — is a continuous thing. And that fact moves it further out along all three axes in the above diagram, into a space that we’re just now beginning to develop algorithmic techniques for exploring.
Written language was still continuous for most of its existence
It’s actually the case that for most of its existence, what we think of as “written language” was also effectively continuous, not discrete. The history of how written language came to be a tokenized, discrete, visual phenomenon is scattered throughout various sources in different disciplines, but I’ll do my best to give a bit of the backstory.
The earliest writing we have is all monumental — public engravings, meant to be read in public. Tombstones, statues, arches, frescoes, and the like were the kinds of places where humans did their writing for most of the history of the written word. This monumental text had an interesting quality down through the millennia that didn’t change until recently: it was largely written in the first-person voice.
The reason these public inscriptions were first-person, is that writing was meant to be read aloud and consumed through the ear. Probably the best compact description of this dynamic I’ve ever read is in the introduction to Jesper Svenbro’s Phrasikleia: An Anthropology of Reading in Ancient Greece:
The writer necessarily depends on the voice of the reader. At the moment of reading, the reader relinquishes his voice to what is written and to the absent writer. That means his voice is not his own as he reads. While it is employed to bring the dead letters to life, it belongs to what is written. The reader is a vocal instrment used by the written word (or by the one who wrote it) in order to give the text a body, a sonorous reality. So when the reader of a funerary stele reads out the inscription “I am the tomb of Glaukos,” logically there is no contradiction, for the voice that makes the “I” ring out belongs not to the reader, but to the stele bearing the inscription. No contradiction is involved, but a kind of violence undoubtedly is.
...for those Greeks, whose reading was always done aloud, the letters themselves did not represent a voice. They did not picture a voice. Only a voice — the reader’s — prompted by those letters could be produced, a voice that, for its part, could claim to represent the voice transcribed.
Not until silent reading was conceptualized — possibly as early as the sixth century B.C. — could writing be regarded as representing a voice. Now the letters could themselves “speak” directly to the eye, needing no voice to mediate.
In Beyond the Written Word: Oral Aspects of Scripture in the History of Religion, William Graham describes how Martin Luther would refer to the “hearing” of scripture, indicating that sacred texts were still read aloud in his day.
Indeed, reading was often done in group settings, with one person reading aloud while others listened on. It was the rise of mass-market print media, where books became a disposable item of individual consumption, designed to be read once then discarded, that really killed these social performances of reading.
Another important thing that mass-market printing did for texts to remove all the earlier vestiges of its heritage as a script for verbal performance. I’m speaking specifically of the elimination of ligatures, and of the liberal use of spacing, punctuation, headings, and other affordances for purely visual consumption.
Many readers have seen pictures of Greek uncial manuscripts, where every page is a giant block of capital letters without even breaks between words:
.jpg")
But if you look at a much later Greek manuscript like the 12th-century one below, you’ll see that even with a lowercase script the word boundaries don’t always align with visual breaks in the text. Ligatures and letter combinations abound, and in general, the text is rendered on the assumption that it will be performed aloud, and that understanding will come through hearing.

Source: The Octateuch
If you have some facility with Greek and think the above script is impossible to read, you’re right. I took a graduate seminar on Byzantine Greek paleography, and while the class was wonderful this particular script was a nightmare for all of us. I found the best approach to this was to just read it aloud, as it was meant to be read, and to listen for the word boundaries.
With the advent of commercial print, when texts came to be consumed silently and rendered in a tokenized form that enabled easier visual scanning, we lost this sense of text-as-vocal-script. As Svenbro says in the quote above, it was then that text itself became the voice.
And I would add, with the disappearance of the performed voice of the author ringing in our ears, we lost an important audible reminder of a key interpretive step we still nonetheless take every time we read.
A quantization theory of writing
Most of us, myself very much included, haven’t really seen the same play performed many times by many different groups of actors. So it’s hard for us to have a real feel for just how much the individual reader brings to the act of reading aloud. The way different words are emphasized, and breathing and pauses are managed, all have a huge effect on the way the text impacts us.
When you experience this first-hand — as I did in graduate school, when I saw the Gospel of Mark (a text I knew very well in the original Greek) performed in its entirety by an actor who had it memorized — it really humbles you as an interpreter of written texts. You realize just how much information is lost when a writer renders her language as text, and how many gaps we readers are filling in without even knowing it.
I would go so far as to say that to read a text is to do very much the kind of filling-in-with-training-data that the PULSE algorithm did to the image of Obama:


A block of written text is an intermediate, quantized representation of a piece of language. As readers, we scale it back up out of our own training, filling in the patterns we think are most adjacent to what has been lost.
This, then, is a kind of picture of the process of written communication:

The writer quantizes a continuous reality down into a sequence of discrete tokens, and the reader reverses the quantization by filling in all the missing cues out of his own values, prejudices, and guesswork.
To read aloud is to work at this upsampling in an explicit, unavoidable way; and to do so in the presence of others is to upsample in a context where others are judging your work, and maybe even silently correcting it.
To read silently is to do that same work swiftly and unconsciously, without the possibility of real-time correction. It’s also to imagine you’re reading an utterance in its native form and to therefore be blind to the fact of its quantization and to the upsampling work you’re doing on it.
We have a long way left to go
I think people in the world of NLP fool themselves about how far we have yet to go by considering the automated manipulation of discrete symbols — no matter how much it resembles the human manipulation of discrete symbols — as the processing of “natural language.”
What we currently have in NLP, rather, is essentially this:
Modern humans have trained themselves to communicate with one another via the manipulation of a discrete set of symbols that enable the writer to downsample and the reader to upsample. (But we through out a ton of critical communicative context in that process.)
Machines can now be trained that manipulate that intermediate, downsampled symbol library in ways that are at times indistinguishable from human communicative activity.
This way of looking at NLP has a few implications:
When the machines generate text, the output was never downsampled from anything continuous — it began life in the discrete realm.
Conversely, when the machines read, they are not upsampling or otherwise expanding something discrete into something continuous.
When humans read (by upsampling) machine-generated, we’re filling in information that was never there to begin with. So there is no “wrong” interpretation of machine-generated text, at least not from the standpoint of authorial intent.
I do not think we will be at the point of “natural language processing” until we’re skipping the intermediate (textual) quantization step. This doesn’t mean the model won’t do any quantizing down into some set of discrete internal representations — I think even the human brain probably does a certain amount of that — but rather that anything recognizable as written text won’t be anywhere in the loop.
For translation, this means speech-to-speech translation. For generative language models, it means expressive analog speech that’s offered either in response to analog human speech (as input) or in anticipation of human action (as feedback).
All of this will take considerably more work — more hardware, more data, and more research — before we get even close to it.
Sourcing the data
We’ll get the hardware and research parts sorted eventually, but finding the training data will always be difficult for privacy-constrained nations. That’s why I think Clubhouse — or something like it — is probably our best hope for this.
With over 10 million users already, the app is probably seeing off millions of hours of conversation per day. As it grows, the pool of available training data will only expand. If we could hitch enough hardware and research to this source of training data, I think we could probably build machines that sound as miraculous as GPT-3’s output looks.