
New Google tool is the whole AI debate in widget form
New Google tool is the whole AI debate in widget form
Humanity's future rendered with colored boxes and sliders

I have now seen the Rosetta Stone for the AI ethics debate. It is everything I’ve been writing about in this newsletter, packaged into a really wonderful interactive tool that’s hosted on Google’s servers:

This newly released project, a Google Explorable, was something both Timnit Gebru and Margaret Mitchell were working on before their departure from Google. Take a moment to look through the demo and play with it, and read the accompanying text. Then come back when you’ve poked at it for a minute.
I want to pull a few main take-aways from this work in this post, though there’s enough here that I could probably keep going on it for considerably longer. That’ll have to wait for future posts, though.
Background: ML basics
It’s important to have a few intuitions about how some popular machine learning models are trained and used before you can grasp what’s going on in the new Explorable. Don’t worry, there is no math here! This section is written for non-nerds.
(Note: What I say in this section doesn’t apply to all types of ML, or even to all neural networks. But my goal here is to develop useful intuitions in lay readers, and not to fully explain the tech.)
In the diagram below, we have a training dataset that represents something in the world — a library of street signs, an archive of chat messages, a collection of pictures of wild plants, etc. For our purposes, this dataset has been cleaned up and maybe even tagged by humans, so at some low level, it has had some structure and meaning baked into it before the machine sees it.
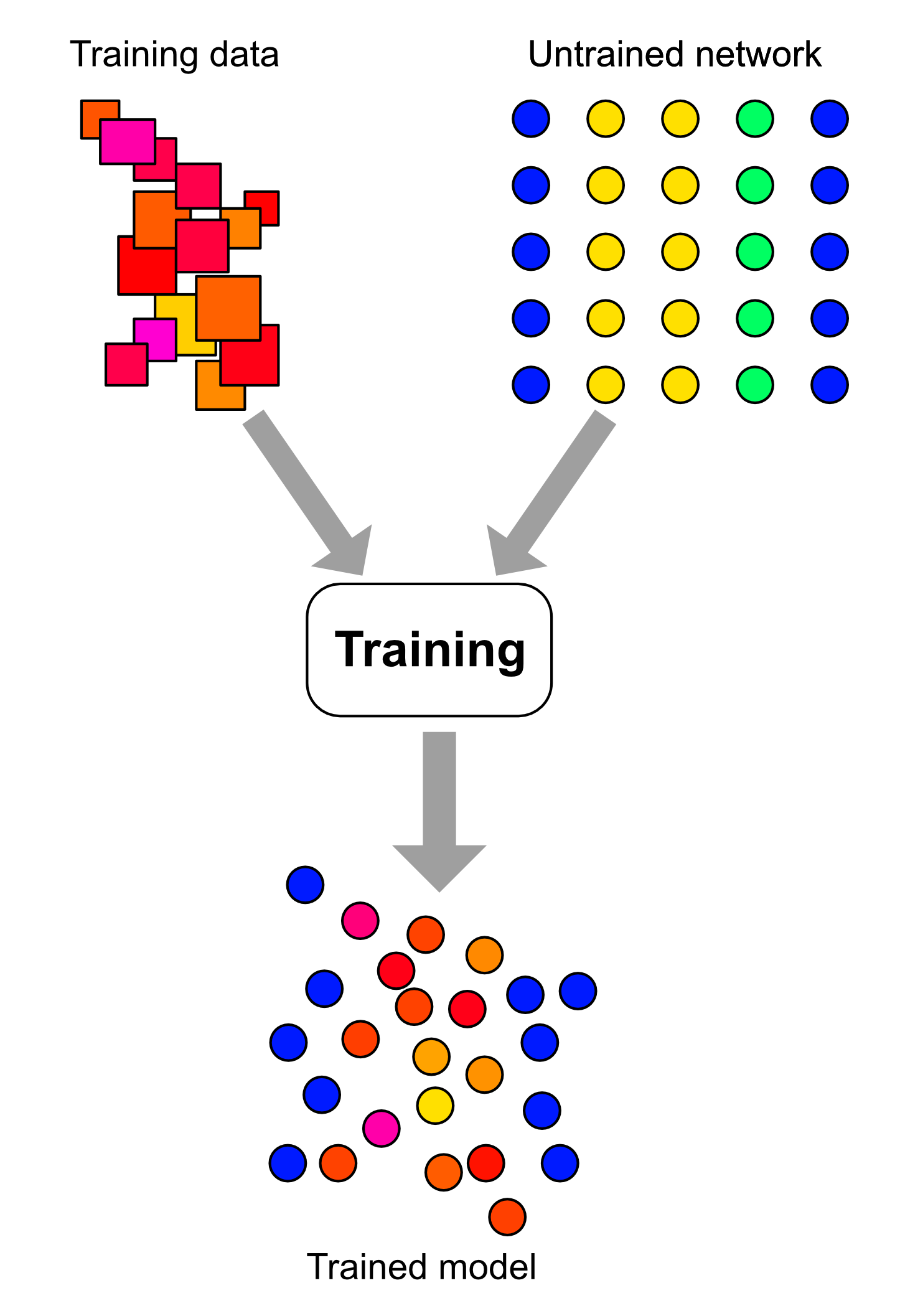
Our untrained model is then trained on this dataset using some kind of training algorithm and over a certain duration of time. Now, this training will shape and alter the model, so that it begins to develop some kind of internal structures that represent certain features and aspects of the training data.
When it’s fully trained, the model’s internal arrangement of weights and neurons now encodes some kinds of knowledge (we may not be sure what kinds until we test it) about the dataset. The model will have inferred patterns in the data and may have even learned some number of novel, higher-order synchronic (when this happens, that also happens) and diachronic (after this happens, that then happens) rules that govern the data and that humans would never have noticed.
In this next diagram, we use the model by giving it some input that it has not seen before, and it’s giving some output that it’s quite similar (but not identical) to part of its training data. Maybe our model is a language model, and we’ve just given it a new configuration of words (along with a brand new word it has never seen), and it’s spitting out a sequence of words that make sense to us as a rephrasing (or even a translation) of the input words.
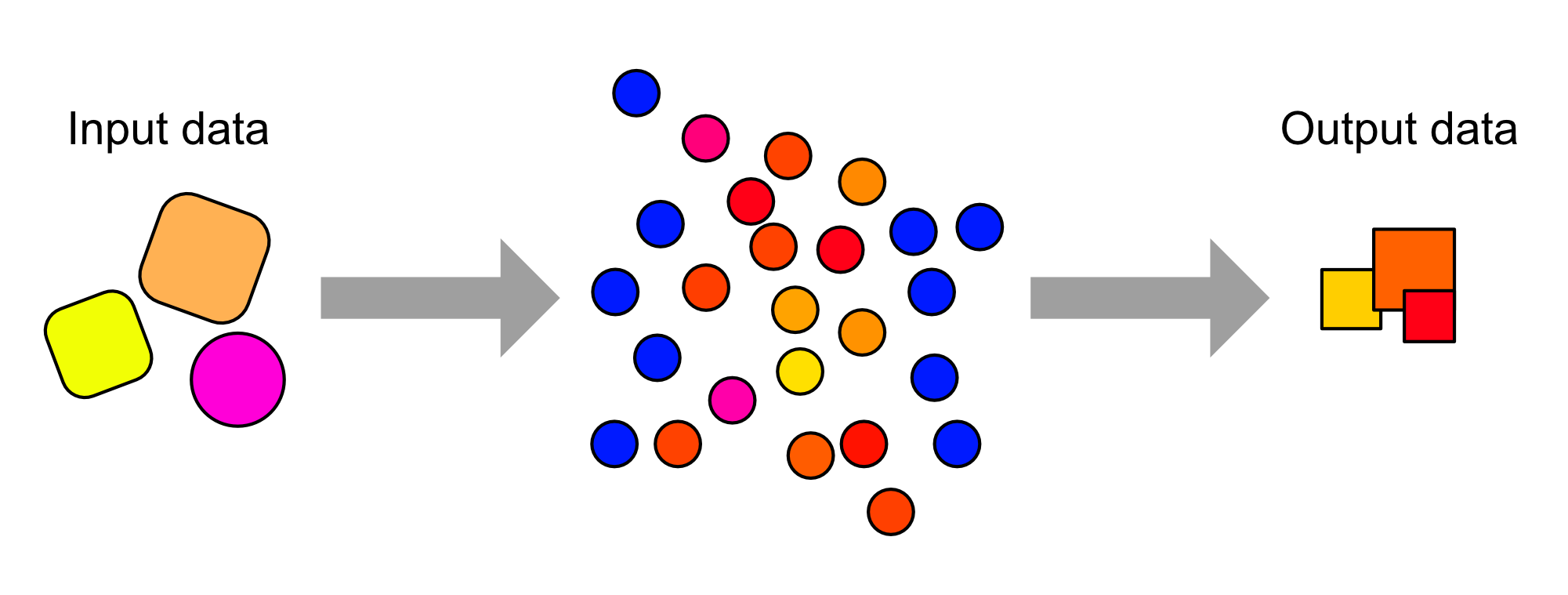
So to summarize, the steps we’ve just gone through are like this:
We collect and curate a set of training data that reflects facts about the world, or represents things in the world.
We train the model on that data, so the model represents knowledge of those facts or things and of the relationships between them.
We use the trained model by giving it inputs and then interpreting its outputs in some way we find useful.
The take-away: The trained model reflects the dataset. More importantly, that model’s output — which we humans may be relying on to discover new facts about the world — also reflects the dataset (among other things).
Year One/Zero
The Explorable’s opener contains a succinct summary of probably 75 percent (at least) of all work on AI ethics (emphasis mine):
Search, ranking and recommendation systems can help find useful documents in large datasets. However, these datasets reflect the biases of the society in which they were created and the systems risk re-entrenching those biases. For example, if someone who is not a white man searches for “CEO pictures” and sees a page of white men, they may feel that only white men can be CEOs, further perpetuating lack of representation at companies’ executive levels.
There are two parts to the text I’ve emphasized:
Datasets reflect the biases of society.
Allowing those dataset biases to be reflected in the model perpetuates them in society.
Let me rewrite these two points in a way that makes plain what’s at stake:
Historical texts, monuments, and symbols reflect the biases of society.
Allowing those historical biases to be reflected in current cultural products perpetuates those biases in society.
I can also rewrite these in yet another way that makes a related point:
Old books and TV shows reflect the biases of society.
Allowing those historical biases to shape young minds perpetuates those biases in society.
This is the struggle we’re currently in across our whole society, is it not?
I think everyone agrees that many parts of our society’s “dataset” (certain written histories, children’s books, statues, flags, etc.) reflect society’s historic biases. The question is, what, if anything, to do about it?
There are many who favor deliberative, incremental changes to the status quo, but you can’t publicly take that position lest you get whacked with certain MLK quote about the “white moderate.”
Then there are those who look at the power of the digital age — the power to erase or rewrite the past with just a few clicks and keystrokes — and think, “if we are on the side of justice, then why should we wait?”
If the inputs into our culture — let’s speak frankly: the inputs that go into the formation of young human minds — are all digital, then what is the moral argument for not sanitizing them immediately?
Keeping backups is about humility
I think there is only one such argument, the argument from humility. This argument requires the would-be sanitizers to cede that, no matter how monstrous certain features of society’s digital dataset seem to them, they may be in the wrong about that. We may actually end up needing what you would delete from the cultural hard drive.

I think very few people — especially not people keen on sanitizing — are willing to entertain the possibility that something they feel in the very core of their being to be an unjust horror is, in fact, righteous, and it is rather they who are on the side of evil in some matter.
Few wokes are willing to “hold space” for the problematic. Few Christians are willing to keep the door open for sin.
Of course, true believers have always been this way. What’s new in this moment is the fact that entire swaths of culture can be cleared from our collective memory with a few keystrokes by someone with the right access. This can be (and is being) done with very little oversight or deliberation, and by a tiny handful of unknown private-sector employees.
This power is new, as is the concentration of it into so few hands.
A digital quota system
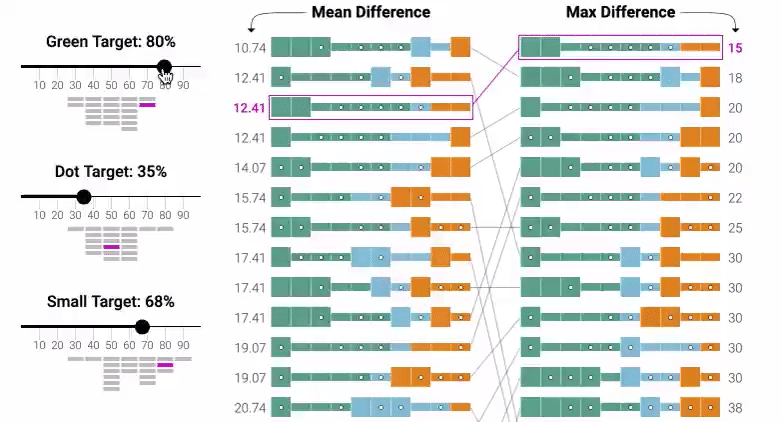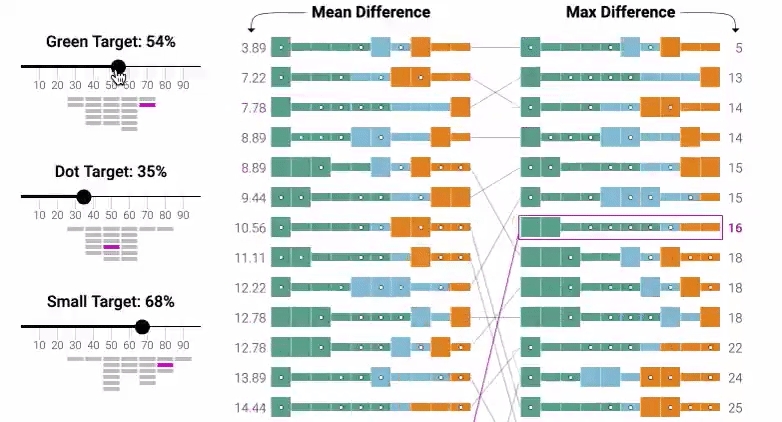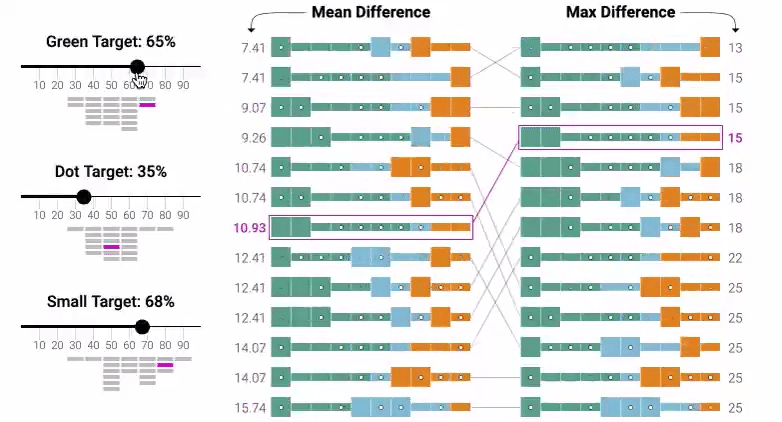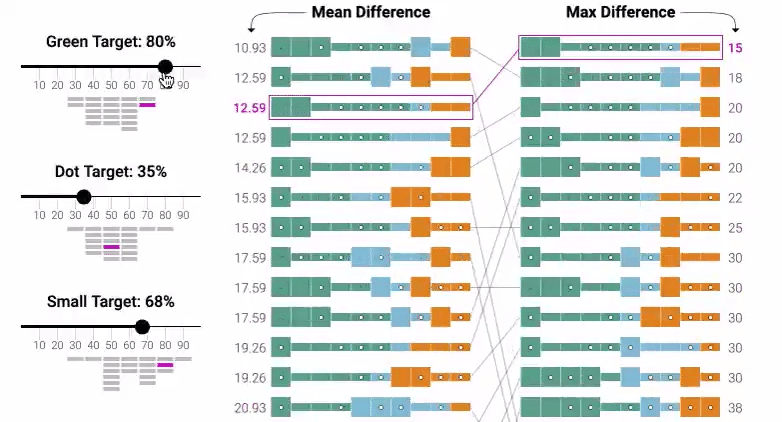
The bulk of the Explorable is quite literally a digital implementation of the classic and much-maligned quota system. The tool, shown in the image below, has set a quota for a certain amount of representation in the dataset and then lets you manipulate the data in order to meet the set quota.
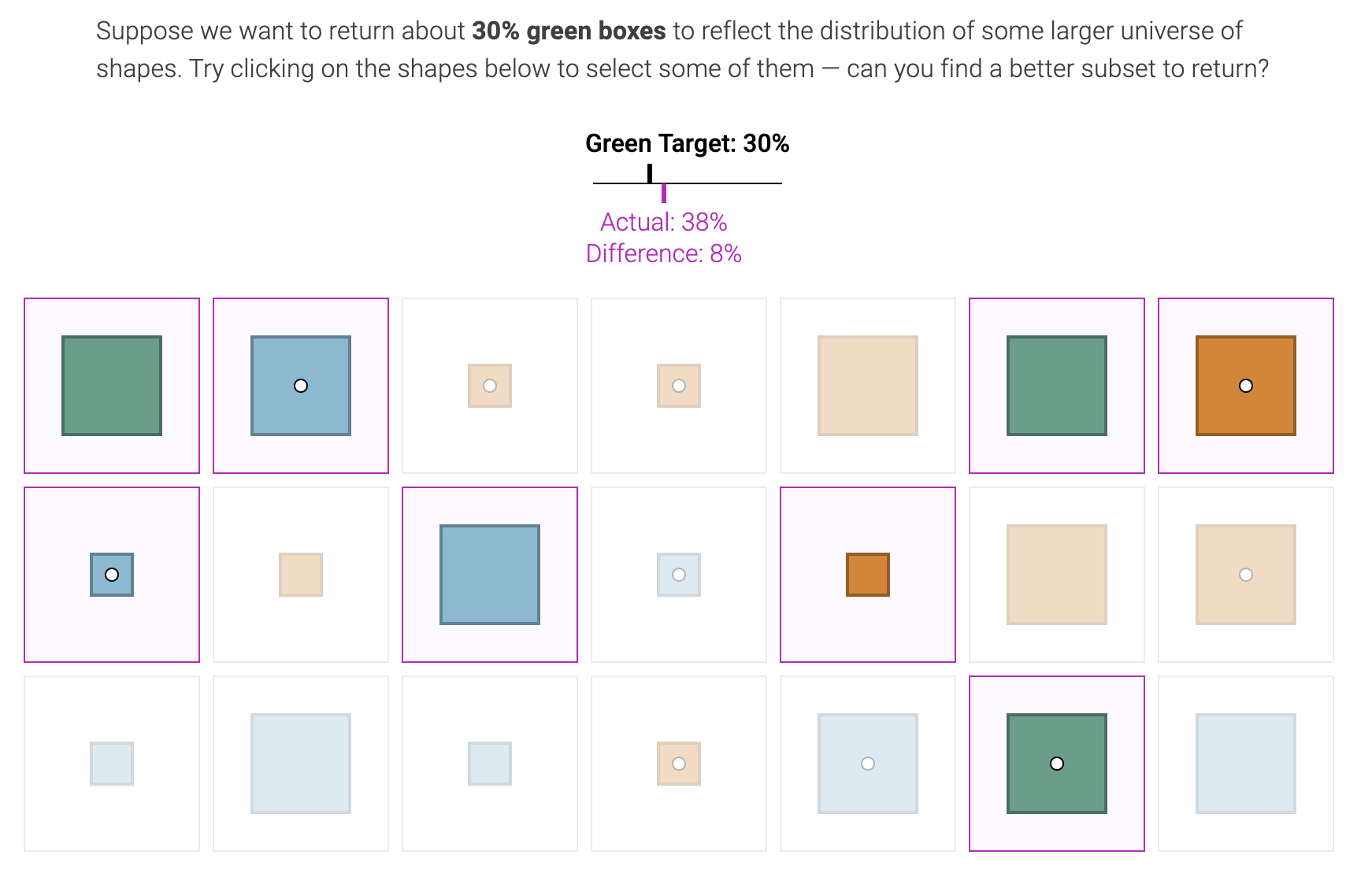
This is very much the fashionable concept of “equity,” rendered in the interactive widget form. The goal of the new-deprecated notion of “equality” was “everyone gets the same chance because the system is blind.” The goal of equity, then, is “everyone gets the same outcome because the system is actively discriminatory in order to meet a target.”
This tool, then, invites you to play at enforcing racial and gender equity at the level of the training data, so that the training data no longer reflects society but reflects the quota that has been imposed by the activists.
In this respect, this widget is a preview of everything digital that is touched by machine learning (which is to say, it’s a preview of everything digital, full stop). There will be quotas, and the social engineering of “equity” will take place at the level of the dataset. So that when society uses the outputs of the trained model, those outputs reflect (and, it’s hoped, perpetuate) the equity that was engineered into them.
Intersectionality is identity as an attribute vector
The truly “meta” part of this work is in the second section, where intersectionality is introduced.
The problem the activists face is that people’s identities aren’t reducible to one single attribute, so you can’t just impose a quota for a single attribute and target that. For the woke, humans are reducible to at least three attributes — race, gender identity, and sexual orientation — so if you’re trying to meet a quota for each of these, then you have yourself a multivariate optimization problem.
Fortunately, we have ample math for exactly this category of problems, and indeed machine learning algorithms have gotten good at it, as well.
Intersectionality, it turns out, takes the mathematics of oppression from the scalar realm into the vector realm. Instead of being identified by a single attribute, you’re identified by an ordered row of them: [race, gender, sexuality].
Intersectionality positions you in multidimensional space; the simple spectrum of privilege becomes a complex manifold of privilege that you can locate individuals on the surface of.
Here’s a screenshot of the more sophisticated tool that lets you play at solving this multivariate optimization problem:
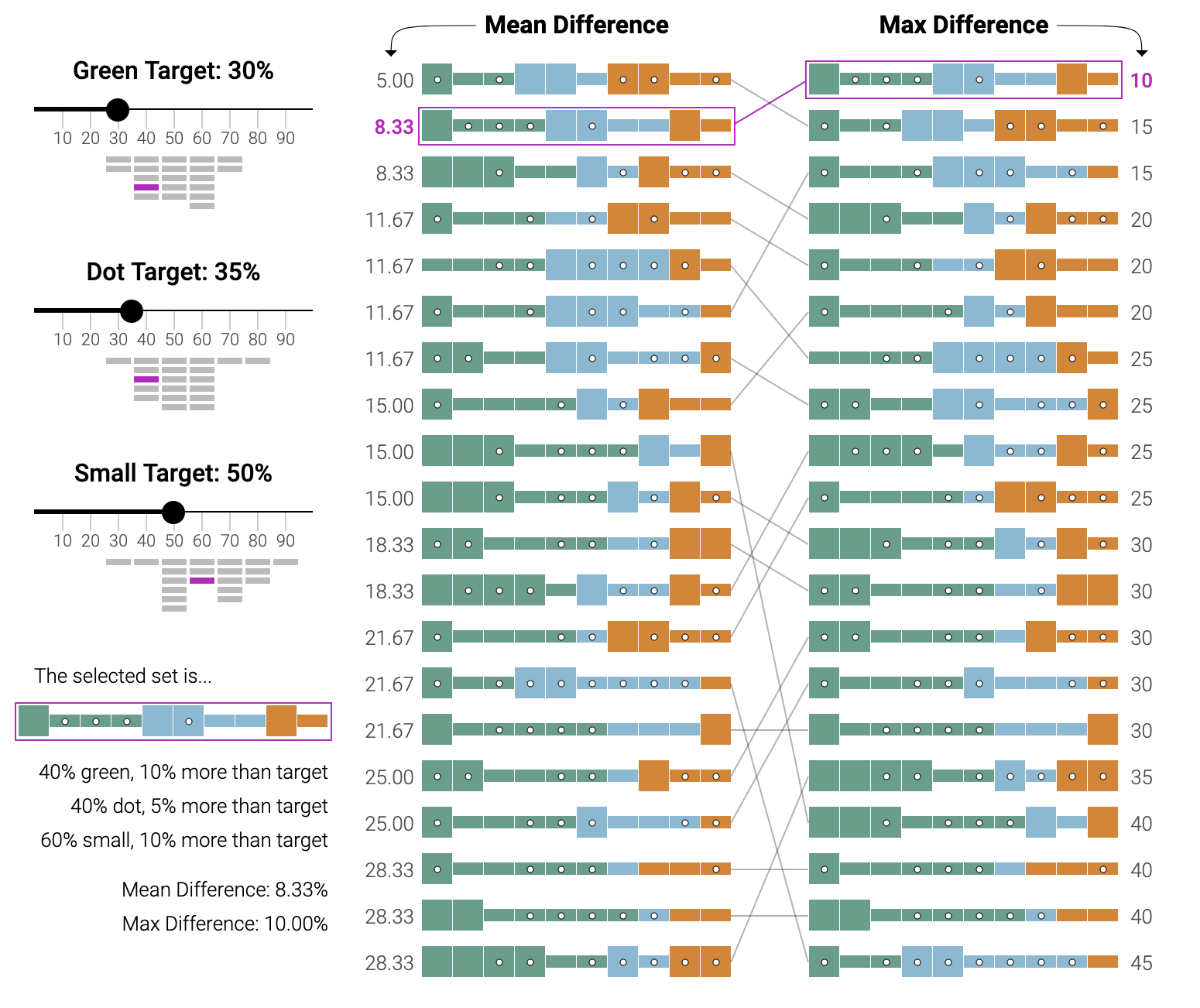
This, too, is the future of the digital age: At some point, some social engineering algorithms will reduce you to a vector of identity characteristics, and the direction of that vector will determine how much you get of some scarce societal good.
Where you fall on the manifold of privilege will determine how close you are to something that many want but only a few can have.
Of course, the woke would argue that the world is already this way and that they just want to use digital technologies to correct that — to achieve equity by changing the shape of the manifold.
If all this bothers you, then the question I have for you is: are you going to stop them? Because this is happening. It is the baseline scenario. If you want things to turn out otherwise, the time to speak up is right now.
Automated gender recognition is only problematic when they say it is
I said above that identitarians reduce identity to three characteristics: race, gender identity, and sexual orientation. You’ll notice, though, that there’s only one of these three considered in the final section of the paper, where the abstract shapes in the widgets give way to real identity characteristics.
That characteristic is gender, and this section contains examples of doctors and construction workers whose “gender presentation” is discussed and classified by the authors.
I put “gender presentation” in scare quotes because I think there’s a bit of jiu-jitsu going on with it. In short, the authors have to maneuver around the objections that the AI ethicists have raised with the very idea that machine learning can or should be used to classify photographs by gender.
In a widely circulated talk on fairness in image processing systems, Timnit Gebru spends considerable time insisting that any attempt to infer gender from photographs is problematic — that the very task of inferring gender from a photo is maybe not one that anybody should use machine learning for.
Gebru takes gender to be an inner, felt reality that can only be expressed and never inferred from appearances.
But of course, the whole premise of this section of the project (which she contributed to) is that not only can you infer something meaningful about gender from photographs, but that it’s actually important to the cause of equity to be able to do so.
What it boils down to, then, is that it’s not only possible but desirable to infer gender from photographs if you’re the right person doing it for the right reasons (i.e. to fit a quota). But otherwise, this entire ML task is problematic.
The two dogs that didn’t bark in this section are the other two identity characteristics: race and sexual orientation. Regarding the former, a lot of the tasks one can imagine using an ML-powered racial profiler for are creepy and bad, so you rarely see this come up (though I did hear someone float it in a Clubhouse room as a way of automatically ordering the speaker queue). And regarding the latter, automated detection of sexual orientation from photographs, it turns out that ML is eerily good at this and that unexpected fact makes everyone unhappy, so it’s now off-limits.
The automated inference of sexual orientation is especially relevant, here. Because in the video above, Gebru touches on ML classification of sexuality and hypothesizes that the machines are merely picking up on certain stereotypical gay male grooming behaviors (then they infer an inner orientation from there). I’d ask her, then, why is that practice not okay, but it is okay for the machines to pick up on certain stereotypical “masculine-presenting” clothing and/or grooming characteristics to infer an inner “gender identity”?
I find this incredibly interesting as someone who doesn't know much about machine learning. Do you have any more information or sources about the detection of sexual orientation via photos? That's fascinating to me and I'm curious about it.