

Why I've grown less skeptical about artificial general intelligence
Why I've grown less skeptical about artificial general intelligence
Scaling our way out of the uncanny valley

I have historically been skeptical of the possibility of humanity discovering an artificial general intelligence (AGI) in my lifetime. But lately, there have been some surprises in the world of machine learning, surprises that have emerged as we’ve built ever-larger models. There’s something weird going on, and there may be even more weirdness in store for us as the models get bigger.
So I’ve begun to (naively) extrapolate from those surprises that we may actually stumble across something like an AGI. Maybe even soon. In this post, I’d like to think aloud on that topic and to invite feedback and pushback from those who work on these projects.
A lot of the conversations that are reflected in this post have taken place “on background” (which in my case means I don’t quote a source, even anonymously, but just use the information in some paraphrased form). So if you’re someone working in this area and want to reach out with more color on anything I’ve covered in this post, please feel free to reach out via email or Twitter.
Skepticism reigns
There are essays that have been written and still could (and should) be written about the varied roles that a possible near-term AGI plays in the secular eschatology of Silicon Valley.
The idea that any day now, some team could hit upon an AGI that would be as big a deal for humanity as the discovery of fire (per Google CEO Sundar Pichai), does more behind-the-scenes work in the world than most people suspect. It drives some of what tech people think are important problems to work on, and increasingly the fear that China will get there first is behind some of Google’s resistance to being regulated or broken up (based on some conversations I’ve had, plus my own inference).
In short, it doesn’t take much imagination to think of ways that an urgent, species-defining race to be the first company or nation to bring an AGI into the world could hide a multitude of capitalist sins. So I think skepticism is warranted, and I have had plenty of it.
And for the most part, skepticism has been the rule among those closest to the topic. While tech luminaries like Pichai and Ray Kurzweil may preach the gospel of a soon-coming AGI — and while the inner circle that runs Google may believe in that gospel (or so I’ve heard) — the actual folks tasked with building such a beast have not historically been very optimistic about their own odds.
The mythical machine-month
A survey of AI researchers done in 2016 indicates a consensus of something like a 50 percent probability of an AGI in the next 50 years.
But 2016 was a long time ago — another era — in machine learning years. So long ago, in fact, that a number of the milestones on the list have already been knocked out well ahead of the consensus schedule:
Play all Atari games: Consensus said about 10 years from 2016, but DeepMind could do this as of April 2020.
Write a high school essay: Not only can GPT-3 as of 2020 write a high school essay better than most high schoolers, but it can actually write a college essay on a level that fools college professors.
Go: This was supposed to be well over 10 years out, but depending on how you adjudicate it, this fell in late 2017 with AlphaZero.
5km Race in City (robot vs human): I’m not sure if Boston Dynamics’ bipedal Atlas robot is quite there yet, but it has to be close. The gating factor on this one is battery tech and energy density, and no so much ML prowess.
You can see from the above that lately we are being surprised to the upside — things are happening faster than expected, and in many cases, the people closest to these projects are surprised at how good the results are.
This is all backward from how software normally works — you can usually double programmer time and cost estimates for meeting a milestone, and even that’s often optimistic. Software milestones just don’t tend to arrive unexpectedly early, especially not in clusters like this. There is something weird happening.
In the past six or so years, across different problem domains (games, language generation, and other areas I’ve been told about off-the-record), neural networks have exhibited an important property that does not seem well appreciated outside of elite circles at a handful of large companies: when a neural network-based model gets to a certain size, a kind of miracle can occur.
The phase transition
Sometimes, when a neural network is scaled past some size threshold (measured in the amount of computing resources and volume of training data), our human assessment of the quality of its output can change in some fundamental ways. A neural net that’s essentially a toy, with brittle, awkward-feeling output and limited usefulness, can morph into a stunningly capable piece of technology simply by throwing hardware and training data at it.
This is true to the point that working with models on the scale of an OpenAI or a DeepMind is a different experience than working with models at smaller scales (or so I’m told). It’s not even just the output that’s different — the questions, answers, problems, and processes all undergo a shift, and according to one researcher I’ve spoken with, it’s almost like big models are a different field of study than everything smaller.

In listening to practitioners in different corners of the machine learning (ML) world describe this scale-based phenomenon to me, it almost sounds like they’re describing a kind of phase transition, like when water goes from a liquid to a gas at a certain temperature. Neural networks in particular seem to have this phase transition ability in a way that other types of machine learning systems do not.
That there essentially two “states” of neural networks (continuing on the analogy of states of matter) — “bigger” and “smaller” — is probably under-appreciated because right now, there are only a handful of these large models in existence at a handful of companies big enough to build them. And the circle of people in those companies that are working closely with those models is small.
Furthermore, models this size are quite new — just in the past few years have they even been possible. So we’ve only just now discovered how different the very large networks are from smaller ones that run the exact same code.
But before going into more specifics, I want to ask a pair of questions I’ve recently been asking ML experts, in the hopes of sparking discussion and soliciting feedback from readers:
What if there’s a third “state” at an even larger scale that we haven’t reached yet? Or a fourth state, or a fifth?
What if one of those states, at some much higher level of scale, is something like an AGI?
The feedback I’ve gotten so far on the above is that there doesn’t seem to be an intuitive reason why the answer to either one would be “no.”
As we push model sizes to ever larger levels of scale — and companies like Google and Facebook are aggressively expanding their models — it seems not impossible that we could encounter an AGI at the next phase transition, or the one after that.
The case of GPT-3
I could try to illustrate this “phase transition” phenomenon in terms of AlphaGo, which managed to jump from the realm of beating amateurs to that of beating pros with just scaling (though more recent versions do have architectural improvements), but where I really want to focus is on large language models (LLMs).
In particular, there was a sudden, scaling-induced jump in output quality from GPT-2 to GPT-3 that even people working in LLMs were not quite expecting.
GPT-2 was interesting and fun, and could produce prose that seemed pretty great “for an AI.” When it was announced back in February 2019, its makers had to work to cherry-pick some really good output — nonetheless, the fact that there was good output there for the cherry-picking was a big deal.
Still, it was brittle. Its creators wrote:
Nevertheless, we have observed various failure modes, such as repetitive text, world modeling failures (e.g. the model sometimes writes about fires happening under water), and unnatural topic switching. Exploring these types of weaknesses of language models is an active area of research in the natural language processing community.
Overall, we find that it takes a few tries to get a good sample, with the number of tries depending on how familiar the model is with the context. When prompted with topics that are highly represented in the data (Brexit, Miley Cyrus, Lord of the Rings, and so on), it seems to be capable of generating reasonable samples about 50% of the time. The opposite is also true: on highly technical or esoteric types of content, the model can perform poorly. Fine-tuning offers the potential for even more detailed control over generated samples—for example, we can fine-tune GPT-2 on the Amazon Reviews dataset and use this to let us write reviews conditioned on things like star rating and category.
But when OpenAI announced GPT-3 — based on the same algorithm, just run on a larger dataset with 10X the parameters and more computing resources — it was so good that its output can fool college professors. Some of its essays certainly fooled me; I read them as they circulated on Twitter and then later learned they had been written by GPT-3.
Indeed, this essay about GPT-3, written by GPT-3, is better than what most undergrads in the US could produce on this topic:





What’s wild is that nobody I’ve talked to seems to really know why GPT-3 is so much better than GPT-2. There’s a classic AI explainability problem going on here, where experts can theorize and conjecture about what’s happening inside the model at one scaling regime vs. what’s happening differently in another, but nobody really has answers.
So this subjective jump in output quality is both surprising and unexplained.
Looking for an inflection point
I recently spent some time poking around at this issue of LLMs and scaling, and specifically reading through a paper on performance scaling of LLMs released by OpenAI a few months before GPT-3 was launched. My goal was to understand not just why this qualitative jump happened, but if it had been measured somehow — if there was a curve with an inflection point that I could study.
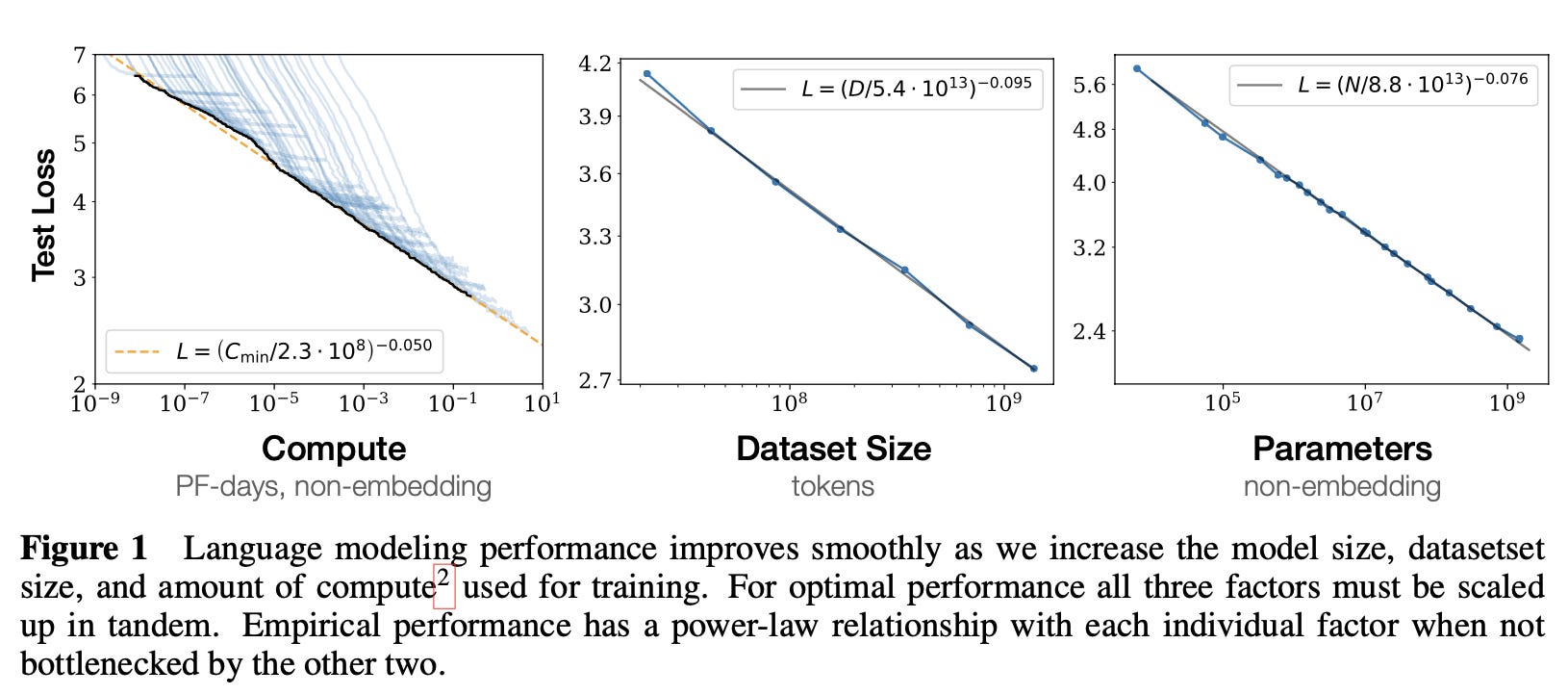
It turns out there is no such curve, at least not in this paper. Sure, there are power-law curves that relate different aspects of the model — scale-related aspects, or parameters related to training and architecture — to performance quantified as a loss function. But that’s not quite what I’m looking for.
The loss function is a kind of training target that measures the degree to which the model’s output falls within an expected range as dictated by the training data. But that is not the same as measuring the degree to which the output corresponds to a human’s gut feeling that a particular output text “smells” like it was written by a human— the relationship between the loss function curve and that latter, more subjective standard of “smells human” has yet to be formally investigated as far as I know.
So when you look at the paper’s conclusion, which is that model size, training data size, and compute resources all have a power-law scaling relationship with performance (as quantified by the loss function), that doesn’t quite tell you much about “performance” framed in subjective human standards of “hey, this reads to me like something a person wrote!”
The uncanny valley
Readers who’ve been around geek culture for long enough will probably recognize what I’m referring to as a “phase transition” as something akin to the uncanny valley phenomenon.
In aesthetics, the uncanny valley is a hypothesized relationship between the degree of an object’s resemblance to a human being and the emotional response to such an object. The concept suggests that humanoid objects which imperfectly resemble actual human beings provoke uncanny or strangely familiar feelings of eeriness and revulsion in observers.[2] “Valley” denotes a dip in the human observer’s affinity for the replica, a relation that otherwise increases with the replica’s human likeness.[3]
In fact, I think what I’m describing probably is the uncanny valley — at its root is a human perceptual phenomenon that just shows up in different realms well beyond the visual/graphics realm where it was first identified.

Source: Wikipedia.
{kind=link}
There are probably any number of domains — from games, to language, to driving, to AI research itself — where if you throw enough resources at a neural network with the appropriate architecture, it passes some inflection point where the output begins to feel human. Or, if “feels human” isn’t the goal, probably because you’re doing something exotic that humans couldn’t ever really do, then “feels godlike” may be a better way of describing the results of this shift.
I wonder if it isn’t also the case that one sufficiently large model could escape from different uncanny valleys in an expanding series of adjacent domains as we throw more computer power and data at it. (AlphaZero is kind of doing this with games.) When the model is large enough, then it feels human for tasks A and B, and maybe even godlike for task C; then a model another 10X bigger adds tasks D through G to its repertoire.
Then what if at some point, we run out of tasks model can’t do in an outside-the-uncanny-valley-like way, and just pack it in and declare it an AGI?
Conclusions
I have a ton more thoughts on this, but I want to cut this post off here and open the floor for discussion and feedback.
Here are some further avenues I’d like to explore in a future post:
Benchmarks: I’m really interested in the relationship between context length in an LLM like GPT-3, and the subjective “feels human” quality of the results. I’m sure there’s something going on there that could probably be quantified, but benchmarking it would involve something rather like a survey — a kind of crowdsourced Turing Test. More generally, knowing when a model has undergone a phase transition on a particular task will involve some cross-disciplinary work with a field like survey design, at least for tasks where the benchmark is “feels human to humans.”
Hardware resources vs. architecture: In most computing contexts, you can substitute clever architectural improvements for hardware resources, and vice versa. I’m sure this holds in ML, where an improvement to the model either unlocks the next level of scaling by removing a bottleneck, or it lets the model get out of an uncanny valley at a smaller resource level.
The China Syndrome: Assuming an AGI is possible, it matters which country gets there first. And whether or not an AGI is possible, it matters if our leaders think it’s possible and are making policy on that basis — especially if fears of China getting there first are factoring in.
Self-supervise learning (SSL): Right now, the models I’ve discussed here all either need humans to label their training data for them or they have a combination of features that makes them more trainable and tractable (discrete, low to moderate dimensionality, low to moderate complexity). This isn’t always going to be the case, though. So it’s worth thinking in more detail about the role SSL might play in the AGI picture.
I remembered your phase transition idea, because it's very appealing to signify emergent capabilities.
GPT-4's ability to self-reflect (something 3.5 can't do) might be such phase transition:
https://www.youtube.com/watch?v=5SgJKZLBrmg
I'm writing a post about the Singularity, arguing that the tools for the self-improvement loops are all here already, self-reflection alone might be enough.